Linear Regression in Go - Part 3
In the previous posts we talked about how to predict a continuous value using a linear function and a way to measure the error given a matrix of test data and a hypothesis set of values theta.
In this post we’re describing a function that will converge the vector theta to its optimal values (or local minimum) which is called gradient descent.
Just to keep things simple, let’s assume we have a vector with just 2 dimensions (slope and intercept values of a simple line). If we plot the graph of , and the result of the cost function we’ll have something like:
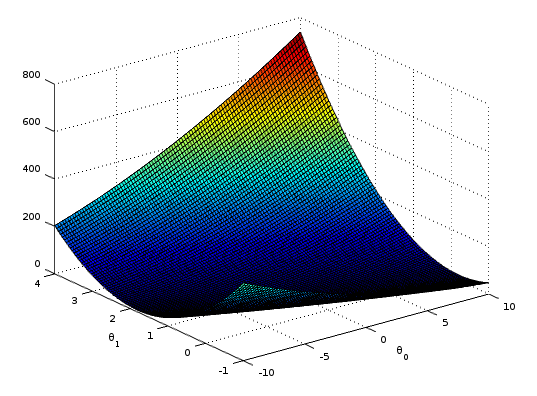
Given any random starting point if we calculate the partial derivative of the function we’ll have a direction pointing away from the local minimum, so we can move a step closer () toward the opposite direction. This is our gradient descent in mathematical terms:
The step we take every iteration toward the local minimum is called learning rate (or sometimes step size ). For now let’s assume we use a fixed value and the same is for the number of iterations we need to perform in order to get to the local minimum.
Deriving this formula results in the following:
or in a more general way (if we assume ):
But what we want to implement is a vectorized version of that formula, which is:
Again, using vectors, the result is much more readable and easier to implement. We can finally get to our actual go implementation:
// m = Number of Training Examples
// n = Number of Features
m, n := X.Dims()
h := mat64.NewVector(m, nil)
new_theta := mat64.NewVector(n, nil)
partials := mat64.NewVector(n, nil)
for i := 0; i < numIters; i++ {
h.MulVec(X, new_theta)
for el := 0; el < m; el++ {
val := (h.At(el, 0) - y.At(el, 0)) / float64(m)
h.SetVec(el, val)
}
partials.MulVec(X.T(), h)
// Update theta values
for el := 0; el < n; el++ {
new_val := new_theta.At(el, 0) - (alpha * partials.At(el, 0))
new_theta.SetVec(el, new_val)
}
}h is a Dense Matrix Vector and numIters is a constant int.
You can find the full implementation here, and tests here.
A good visual explanation is in the following video by prof. Alexander Ihler:
Edit (feb 6 2016): I’ve fixed the code so now h and new_theta are of type Vector instead of DenseMatrix.